GET A FREE CONSULTATION








Posted by Bakul Sengal
January 13, 2017
Everybody knows what is search engine optimization and the importance of a well-structured site, relevant keywords, quality content, proper tagging, clean sitemap and other technical standards. But there are chances, you have not thought about Crawl Optimization.

Crawl budget optimization is some thing that goes a level deeper than search engine optimization. While Search engine optimization is more focused upon the process of optimizing for user’s queries, Crawl optimization is focused on how the search engine bots (web spiders) accesses your site.
In this article, we’re going to walk through the mechanics behind how search engines assign crawl budgets to websites, and tips to help you make the most of your crawl budget to maximize rankings, organic traffic and most importantly indexation.
Crawl budget is simply the amount of pages the search engine spider will crawl your website in a given time period. The crawl budget is generally determined by the size and health of your site and the number of links pointing to your site.

Crawl budget is an important SEO factor which is not often paid enough attention. Search engines use spider bots to crawl web pages, gather information and add them to their index. Further, they also point out links on the pages they visit and attempt to crawl those new pages also.
For example, Googlebot is the web spider that discovers new pages and adds them to the Google index. Most of the web services and SEO tools trust these web spiders to gather useful information.
A website’s crawlability is a primary and crucial step to ensure it’s searchability. If you’re wondering whether or not optimizing the crawl budget is important for your website, the answer is of course YES. Your SEO efforts and crawl optimization will probably go hand in hand.
As simple as it is, It’s quite logical that you should be concerned about crawl budget because it makes easier for Google to discover and index your website. If there are more crawls on your website, means you’ll have faster updates when you publish new content. So, the bigger your crawl budget, the faster this will happen.
This will also help you improve overall user experience for your website, which improves visibility, and ultimately results in better SERPs rankings. The fact is that the pages which have been crawled recently get more visibility in the SERPs and if a page has not been crawled in a while it will not rank well.
It’s not that Crawl budget will often create a problem. If you’ve allocated proportional crawls for your website’s URLs, it’s not an issue. But let’s say, your website has 200,000 URLs and Google crawls only 2,000 pages a day on your site, then it could take 100 days for Google to identify or update the URLs – now this is an issue.
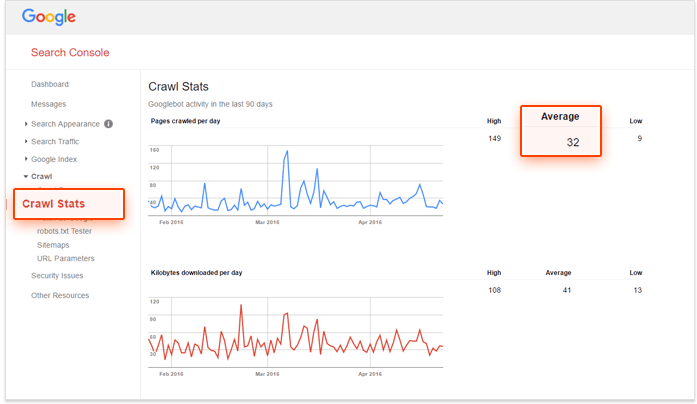
If you’re looking for a solution and want to check whether your crawl budget needs optimization, use Google Search Console and the number of URLs on your site to calculate your website’s ‘crawl number’. How to do this?
– First, you need to evaluate how many pages are there on your website, you can do this by doing a site: search on Google,
– Second, go to your Google Search Console account and go to Crawl, and then Crawl Stats. If your account is not configured properly, you will not get this data.
– The third step is dividing the total number of pages on your site by the average number of pages crawled per day on your website.
If this number is greater than 10, you need to look at optimizing your crawl budget. If it’s less than 5, bravo! You don’t need to read further.
Today, the importance of site structure is a crucial factor. SEO masters like Rand Fishkin advice to make sure that your website’s users are not more than three clicks away from home page during their visit. It’s really a great advice for SEOs in terms of usability as your visitors are not likely to dig deeper into your website.
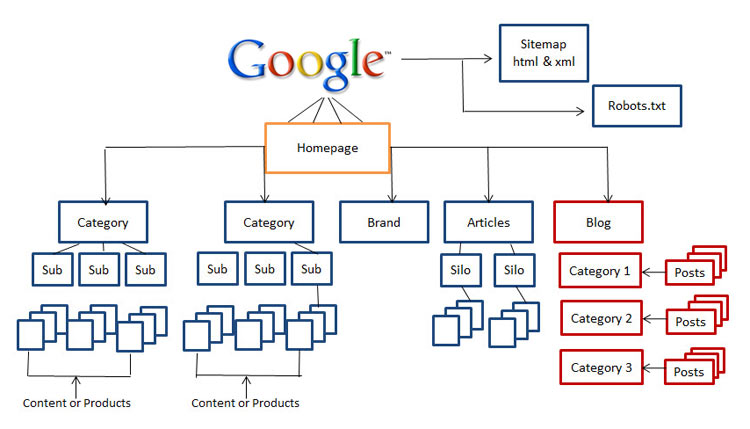
So, if you don’t have a clean, easy to navigate and search engine-friendly website, now its time start restructuring your website.
This is one of the basic difference between search engine optimization and crawl optimization not only broken links play a substantial role in dropping your rankings down, they also greatly impede Googlebot’s ability to index and rank your website.
Google’s algorithm has improved substantially over the years, and anything that affects user experience is likely to impact SERPs. Google has always been trying to copy the user behavior and update the algorithms. So we should always consider the user experience when we are optimizing websites for the search engines.
Today, Google struggles to crawl through Silverlight and only some other files, but there were times when Google couldn’t crawl rich media content like flash, javascript and HTML.

However, although Google can read most of your rich media files, there are other search engines which may not be able to. This means you should use these files wisely, and sometimes you may want to avoid them entirely on the pages you want to be ranked.
Make some efforts to clean up your sitemap and keep it up-to-date in order to safeguard from clutters which may harm your website’s usability including blocked pages, non-canonical pages, unnecessary redirects and 400-level pages. Using XML sitemaps is the best way to help your users as well as spider bots.
There are various tools on the market to clean up your sitemap. You can use XML sitemap generator to create a clean sitemap that excludes all the pages blocked from indexing, find and fix things like 301 and 302 redirects and non-canonical pages.
Link building is an all-time hot topic and is not going away in near future. Discovering new communities, establishing relationships online and building brand value are some of the perks you should already be having on your link building process.
When done through best practices, external links are the links that point external domain and the most important source of getting higher rankings. Though external links are the hardest metrics to manipulate, they are a great way for search engines to know the popularity and relevancy of a web page.
Although Internal link building does not have much to do with crawl budget optimization, this doesn’t mean you can ignore it. A well-organised and maintained site structure helps your content easily visible to the users as well as the spider bots without spending enough crawl budget.
A well-structured internal linking system also enhances user experience. Helping users to reach any area with a few clicks and making things easily accessible will generally make visitors stay longer on your website, which will improve your SERP rankings.
Various feeds such as RSS, Atom, and XML help your website to deliver content to users even when they’re not browsing your website. This is the best way for users to subscribe to most favourable sites and get regular updates whenever new content is published.
Since a long time, RSS feeds are proven to be a good way to boost your website’s readership and engagement. Besides, they are also among the most visited sites by Google’s web spiders. When your website has an update you can submit it to Google’s Feed Burner so that you’re sure it’s properly indexed.
Each URL you’re redirecting to will be wasting a little of your crawl budget. When your website is having long redirect chains, which means having large number of 301 and 302 redirects in a row, then web spiders may drop off before they reach your destination page, ultimately your page won’t be indexed. If you’re looking the best practice with redirects, it’s better to have as few redirects as possible on your website, and no more than two in a row.
If search engine spider bots are able to find your web pages, find and follow links within your website, then they’re crawlable. So, you need to configure your robots.txt and .htaccess files so that they do not block your website’s critical pages.

You may also need to provide the text files of the pages that stand on rich media content like flash, silverlight, etc.
Only by disallowing in the robots.txt, you can not guarantee to stop a page from being deindexed. If there are external things like incoming links which continue to direct traffic to the page that you’ve disallowed, Google may consider that the page is still relevant. In this case, you’ll need to manually block the page from being indexed. You can easily do this by using the X-Robots-Tag HTTP header or the noindex robots meta tag.
Note that if you use noindex meta tag or X-Robots-Tag, you should not disallow the page in robots.txt, The page must be crawled before the tag will be seen and obeyed.
Conclusion: Crawl budget optimization is not an easy task, and it’s certainly not a ‘quick win’. If you have a small or medium sized website, that’s well maintained, you’re probably fine. But if you have a complex and unorganized site structure with thousands of URLs, and server log files go over your head – it may be the time to call professionals or experts to help you out.